
Building a More Resilient Future for Threat Detection

Pick your favorite breach or famous security incident and you'll notice that among the multiple issues that allowed it to happen (it's never just one thing), failing to detect the threat is always there. These multiple failures in detecting threats are, in my opinion, a strong indicator that current threat detection systems are often brittle, not resilient. The crucial concept of resilience, defined as the degree to which a system continues to perform its critical functions under disturbance or its ability to successfully adapt to stressors, is paramount for effective threat detection. In the cybersecurity context, resilience refers to an organization's capacity to prevent, withstand, and recover from incidents while maintaining essential business operations, even when cyber defenses are compromised. This implies that incidents are inevitable and controls will sometimes fail. This is the strongest argument for a robust threat detection and response practice, and still, those practices are also subject to failure and need to incorporate resilience too.
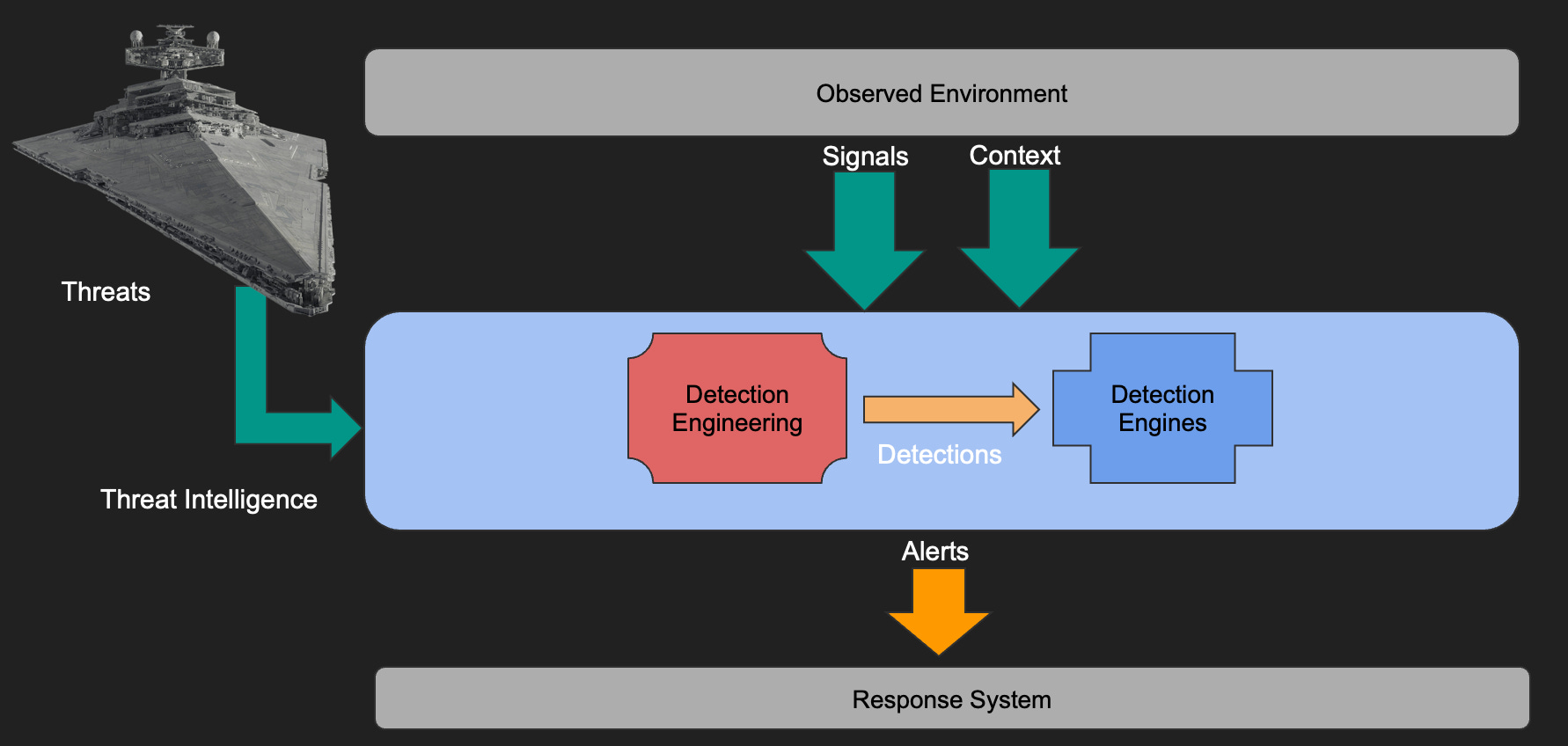
Threat Detection as a System
A threat detection system functions by ingesting signals and context from the observed IT environment, alongside threat intelligence. Detection engineering processes these inputs to create "detections" (rules, use cases, signatures), which detection engines then apply to identify malicious activity and generate alerts for a response system.
I used Kelly Shortridge and Aaron Rinehart's “template” for a system's resilience statement to define Detection resilience as "the resilience of threat detection systems against detection failures, caused either by random component failures or intentional attacker behavior so that the organization can detect threats as they occur". The core idea is to expect security controls to fail, including components of the detection system, and prepare accordingly, focusing on the ability to quickly and effectively adapt rather than attempting to completely avoid them, so you can keep your ability to detect threats functional.
Where Threat Detection Breaks
Threat detection systems are prone to several failure modes that compromise their resilience.
One of those is about brittle detections. Detections are often too specific, failing to adapt to minor deviations in threat behavior or the signals they generate. These detections commonly rely on simple boolean logic, such as "if A and B happens, alert," or straightforward pattern matching, frequently seen in IOC matching. Similarly, detections based on fixed thresholds, like alerting if more than 100MB is sent outbound, would fail if a clear data exfiltration attack happens to transfer only 99MB, highlighting their inherent fragility.
Another common failure point arises from the focus on choke points in attack paths. While it is reasonable to concentrate detection efforts on these critical junctures, especially when triage and investigation resources are expensive, doing so creates single points of failure for detection. If an attacker finds a way to bypass a choke point (rare, as choke points are exactly the points that are harder for the attacker to avoid, but it's possible), the entire attack can go undetected. Even if a bypass is unlikely, failures affecting the generation of the necessary telemetry at these choke points can also lead to blind spots.
Threat detection systems also suffer from single layer coverage, meaning an over-reliance on a particular type of detection technology. This is frequently observed as "endpoint dependency," where most detections are built for EDR due to the rich telemetry available. However, not all attacks touch endpoints, and EDR deployments are not completely reliable; the average EDR coverage for endpoints is only 72%, leaving 28% of endpoints exposed. Similar issues can arise in SIEM-focused organizations, where an average of 13% of SIEM rules are broken and never fire. The trend towards "platformization," or relying on a single vendor for multiple security components, can exacerbate this vulnerability, as a flaw or corrupted piece of intelligence in that vendor's system could lead to widespread detection failures across the entire environment.
Excessive tuning is another problem that undermines detection resilience. Threat detection is fundamentally a classification problem, balancing precision (reducing false positives) and recall (reducing false negatives). Because the cost of dealing with false positives is high and SOCs are often overwhelmed, detection engineers tend to over-tune rules for precision, prioritizing it over recall. This focus on reducing alert volume inadvertently increases the chance of false negatives, causing actual threats to be missed due to an effort to optimize resource management.
The practice of signals filtering also introduces vulnerabilities. To reduce the costs associated with ingesting massive volumes of telemetry into detection engines, organizations often apply aggressive filtering, aggregation, field trimming, and truncation. While this optimizes resource utilization and reduces costs, it heightens the risk of inadvertently discarding essential data needed for detection, creating "unconscious blind spots". This cost-saving measure can severely compromise the system's ability to detect threats.
Finally, brittle pipelines represent a critical failure point. Threat detection technologies are often oblivious to issues within the data pipelines that collect and transport signals from the environment to the detection engines. Problems such as data not flowing, missing agents on assets, or incorrect API credentials can lead to silent blind spots, where the detection system is simply unaware that crucial telemetry is absent. These pipeline failures silently degrade detection capabilities, leaving organizations vulnerable without immediate awareness.
Principles for Resilient Threat Detection
Addressing these vulnerabilities requires a multi-faceted approach, emphasizing awareness within security operations teams about detection resilience and improvements across architecture, detection engineering, response throughput, and testing.
Principle 1: Resilient Detection Architecture
The architectural foundation of threat detection must enable resilience. This involves ensuring threats and assets are covered from multiple angles, as exemplified by the SOC visibility quad (Endpoint, Logs, Network, Application). This multi-layered approach, including EDR for endpoints, SIEM for logs, NDR for networks, and ADR for applications, allows for detection even if one layer is compromised or lacks visibility. For instance, an attack missed at the endpoint could still be caught by log or network analysis. Additionally, resilient architecture demands instrumentation for early failure and degradation detection within the detection pipeline, along with the use of buffers to prevent data loss during minor disruptions. When aggressive filtering is applied, organizations should also leverage alternative data repositories, such as cheaper cold cloud storage, to store full fidelity data for retrospective analysis, thus compensating for primary filtering.
It is also crucial to identify the detection system’s safety boundaries, which include both process thresholds (like triage volume and risk acceptance levels) and system thresholds (such as data volume, alert volume, and detector health). Understanding these critical limits helps anticipate system failure and react proactively, preventing surprises when the system is under stress. Furthermore, applying resilient-friendly architecture patterns like decentralization, redundancy, and loose coupling is vital. Loose coupling, for example, makes detection content production independent from specific tools and abstracts tool functionality, enhancing flexibility and reducing dependencies.
Principle 2: Resilience Embedded in Detection Engineering
Detection engineering practices must actively consider resilience implications in the design of detections. Engineers must balance precision and recall, moving beyond an excessive preference for precision, even if it means accepting a higher level of false positives. Integrating heuristic and dynamic approaches alongside simple boolean logic and static IOCs is also essential. Adaptive methods like anomaly detection and machine learning-driven UEBA are more resilient to minor variations in attack techniques than fixed thresholds.
While choke points are useful for prioritizing detection development, they should not be seen as a means to optimize coverage. The focus should be on broader detection coverage, using choke points to highlight more critical alerts. Aligning detection efforts with the "pyramid of pain" by focusing on TTPs rather than brittle IOCs is paramount for long-term effectiveness. Detection engineers must adopt a mindset that expects certain detection engines and detections to fail, designing systems with redundant coverage and alternative methods in mind. Finally, establishing robust continuous feedback loops from incident response to detection engineering is necessary to learn from missed detections and false negatives, iteratively improving content and strategies.
Principle 3: Increase Response Throughput
Insufficient capacity to handle alerts directly undermines detection resilience by forcing aggressive filtering and tuning. Traditional, human-intensive SOC models cannot provide the necessary throughput for resilient detection. Leveraging automation, particularly AI SOC tools, such as Prophet Security, is crucial for accelerating alert triage and initial investigation steps. Even if these tools are not fully autonomous, they significantly improve the number of alerts a SOC can manage, allowing for broader detection coverage without being overwhelmed and reducing the need for excessive tuning.
Principle 4: Apply Chaos Engineering
Continuous testing is essential to proactively identify resilience issues within detection systems. This can involve "live" testing with CTEM tools and continuous pentesting in production environments, with automation playing a key role in increasing efficiency. Tabletop exercises can complement live testing by simulating scenarios where detection capabilities might be degraded, such as the loss of EDR visibility. Experiments should be designed using a template like: "In the event of condition X, we are confident that our system will respond by Y," which for detection systems translates to: "If the attacker does X, we are confident that we will detect it with detector Y and detection Z". This also includes testing the confidence that triage will properly identify true positives.
“This is the beauty of SCE: by conducting specific experiments, you can test hypotheses about your system’s resilience to different types of adverse conditions and observe how your systems respond to them” - K. Shortridge / A. Rinehart
Chaos experiments are distinguished from typical tests by supporting resilience (rather than just robustness), being sociotechnical (including humans), system-focused, capable of being run in production, random or pseudorandom, addressing adverse scenarios, observing and learning from failures, and considering N-order effects. The primary goal of these experiments is to maintain critical functions under disturbance rather than solely preventing component failure, minimizing the consequences of surprises rather than minimizing the probability of damages.
Bonus Principle: Deception
Deception technologies offer a powerful way to add resilience to threat detection systems. They often generate signals directly tied to threat behavior, which reduces their dependency on the primary, potentially brittle, signals pipeline. Deception artifacts can cover numerous attack paths, acting as "natural choke points" that increase detection chances even without specific, pre-built detections. Furthermore, deception can be deployed across the entire SOC visibility quad, including network honeypots, honeytokens for identity, and application-level deceptions.
The Path Forward: A Nascent Area of Continuous Improvement
The journey toward truly resilient threat detection is still in its early stages. While significant progress can be made by adopting the principles outlined above, much work remains. Future endeavors should focus on evolving these principles to provide more specific guidance, developing standardized reference architectures, and enhancing processes for building less brittle detections within the detection engineering pipeline. An ambitious concept to explore is "anti-fragile" threat detection systems—systems that not only withstand stressors but become stronger and more capable when subjected to them.
By embracing a resilience-first mindset, understanding common failure points, and strategically applying architectural, engineering, operational, and testing principles, organizations can significantly improve their ability to detect threats. This should be an ongoing conversation and a critical area for continued research and development.
Many ideas and concepts directly borrowed from Kelly Shortridge and Aaron Rinehart's “Security Chaos Engineering”.